Collation involves the detailed note-by-note comparison of all the witnesses in order to identify and record variants between them. To ensure that we are always comparing like with like, we collate all witnesses against a common baseline, which we call the ‘control’. The control is usually the version that Kenneth Gilbert chose as the ‘copy text’ for his complete edition. This is, for the most part, the Essercizi for K1-30, and Venice, occasionally Parma, for the remainder. It is important to emphasize that we do not collate against Gilbert’s published text itself, but against the witness he used as the basis for that text.
Wherever possible, each collation is done twice by two colleagues working independently. Their work is then checked and corrected by a third person—a process we call ‘validation’—making nearly one million bars of music to be examined in total. This labour-intensive approach is necessary because current Optical Music Recognition (OMR) technology cannot accurately process manuscript variants of the complexity that we find in Scarlatti sources. This point is illustrated in Ife et al. 2024Ife, Barry, Jasper Van Der Klis, Jérémie Lumbroso, Marco Moiraghi, and Luisa Morales. 2024. ‘“Texting Scarlatti”: Unlocking a Standard Edition with a Digital Toolkit’. Journal of New Music Research, October 15, 259–76. https://doi.org/10.1080/09298215.2024.2408266. , figure 1.
In order to get the work done in the time available we have therefore relied on a team of some 30 paid volunteer research assistants, many of them postgrads and performers, working entirely online and in their own time (their work is acknowledged in the Credits section of this website). This part of the project has been supported from Research England ‘Participatory Research’ funds.
Variants between each witness and the control are recorded on Google Sheets using a code that we have devised for this purpose. This is documented in a comprehensive User Manual which is revised and updated as new situations arise. Nearly 190,000 variants have been recorded in this way.
Each Google Sheet has two main sections: Header and Bars. The Header section records, column by column, basic metadata about each witness of each sonata—tempo, key and time signatures, number of bars, range, types of ornamentation, etc. This allows longitudinal comparisons to be made. The top row of the Header also includes links to images of each witness for that particular sonata, both for the convenience of those collating and for anyone who wishes to check our work for themselves—a wise precaution that we strongly recommend.
Despite our best efforts, one institution has decided not to make their images publicly available. While it is still possible to consult our data for these collections, it is unfortunately not possible to consult the manuscripts themselves.
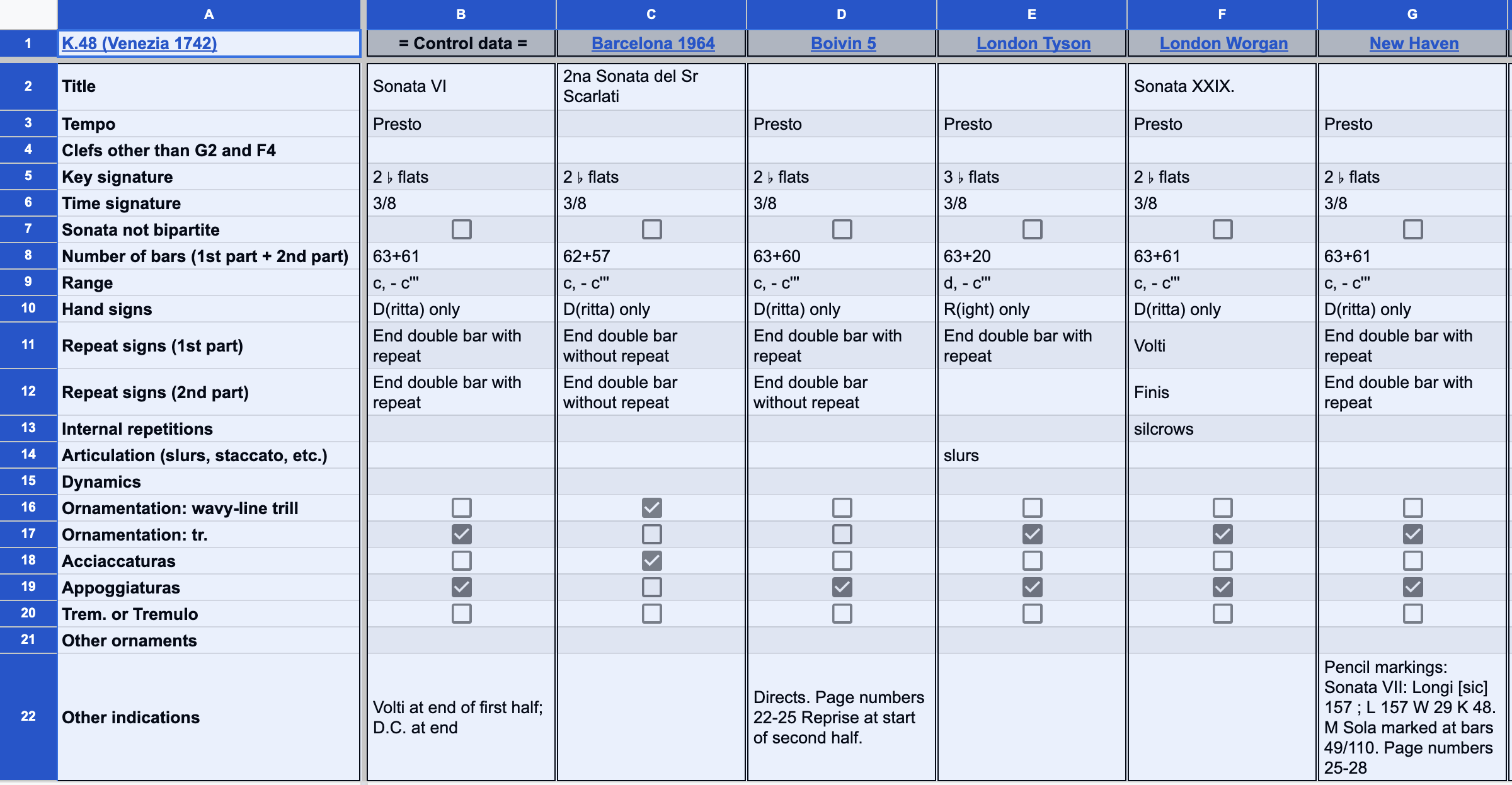
This screenshot shows part of the Header section of K48:
- Accents
- Hand signs
- Articulation
- Ornaments
- Bars: absent or added
- Other indications (e.g. mutandi = change fingers)
- Duration
- Pitch
- Dynamics
- Rests
- Expression
- Slurs and ties (presence or absence)
- Fermatas
- Stems (only when a stem is added or removed)
- Grace notes
- Tuplet signs (triplets, sextuplets)
Our code is designed to be quick and easy to use, is predominantly alphanumeric, does not use musical notation, and is therefore machine-readable as well as legible by human beings. It consists of the two main elements common to all types of critical apparatus: the lemma and the reading, separated by a closing square bracket:
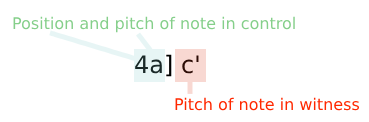
In this example the 4 indicates the position of the note in the bar and the a indicates the pitch (the a below middle c using the LilyPond convention); c’ indicates the pitch of the variant, in this case, middle c. So, taken together, this short piece of code means ‘the fourth note in the bar in question, which is an a below middle c in the control, is middle c in the witness’.
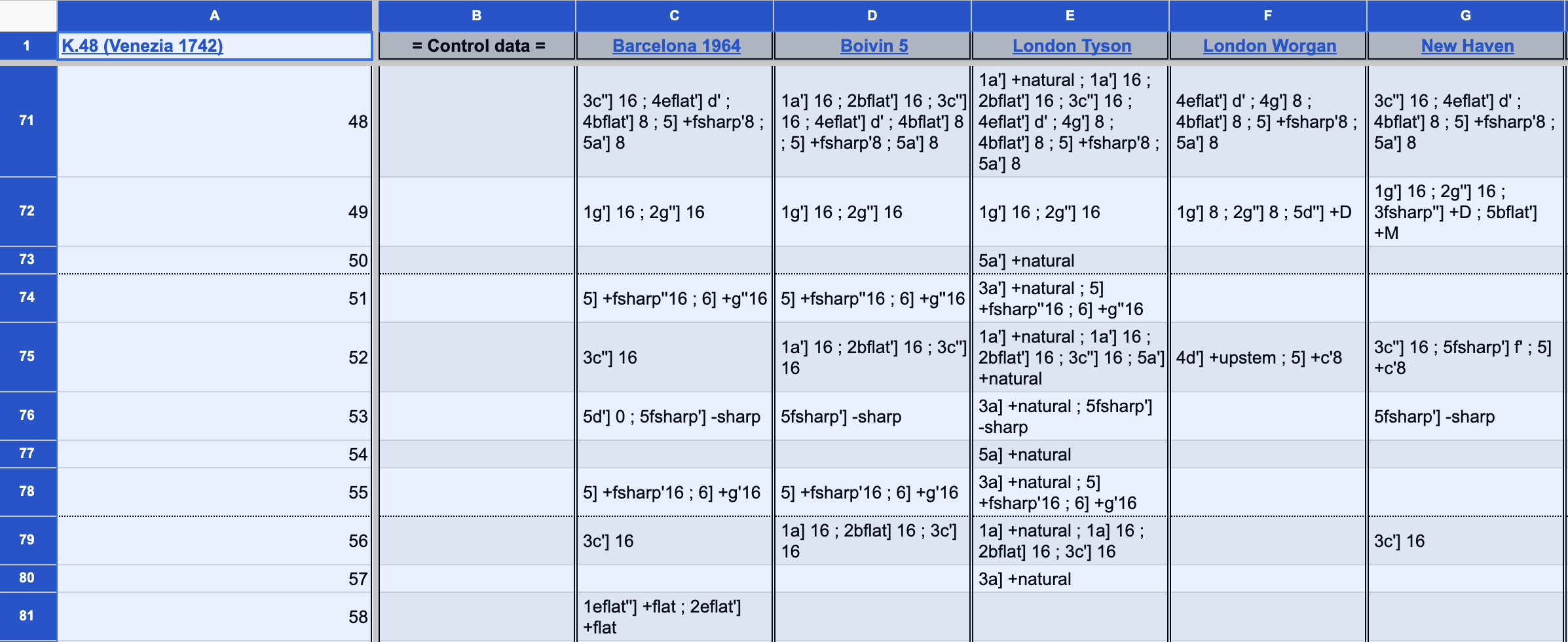
This screenshot shows part of the Bars section of K48 (bars 48-58):