By this stage we have recorded nearly 190,000 variants, which is far too many for a human being to assimilate. Visual inspection of an individual spreadsheet, together with the scores from which it is derived, can stimulate insights about a particular sonata; but for larger-scale analysis across the complete corpus, further processing of the data is required. One of the benefits of using Google Sheets for recording variants is the ability to extract the data in the form of JSON (JavaScript Object Notation) files which even a desktop computer can read and analyse at breath-taking speed. The modern desktop computer or laptop can read all the data from the 555 individual spreadsheets, extract and count the variants, prepare them for phylogenetic analysis and run a one-to-one comparison on some 3300 witnesses, in under ten seconds.
A principal area of investigation for this project has been kinship between individual witnesses, pairs, groups or whole collections. As with traditional textual criticism, analysis of this kind is based on the forensic principle that all contact involves transfer. In our case, this means that a copy is never the same as its original text or ‘exemplar’. Copyists will always introduce changes, whether in error or as the result of conscious or unconscious attempts at interpretation or improvement. Such changes are the textual equivalent of DNA, and variants in common between one or more witnesses may be a marker of kinship. For this reason, we have been guided by other projects that have used phylogenetic software from the biosciences to establish kinship between texts, both literary and musical (see Windram et al. 2014Windram, H. F., T. Charlston, and C. J. Howe. 2014. ‘A Phylogenetic Analysis of Orlando Gibbons’s Prelude in G’. Early Music 42 (4): 515–28. https://doi.org/10.1093/em/cau100. and Windram et al. 2022Windram, Heather F, Terence Charlston, Yo Tomita, and Christopher J Howe. 2022. ‘A Phylogenetic Analysis of Two Preludes from J. S. Bach’s “Well-Tempered Clavier II”’. Early Music 50 (3): 373–93. https://doi.org/10.1093/em/caac027. ).
An essential first step is to have the computer analyse all the variants by sonata, by type and by closeness of match. This is an extract from a typical summary table of variants, in this case for K48:
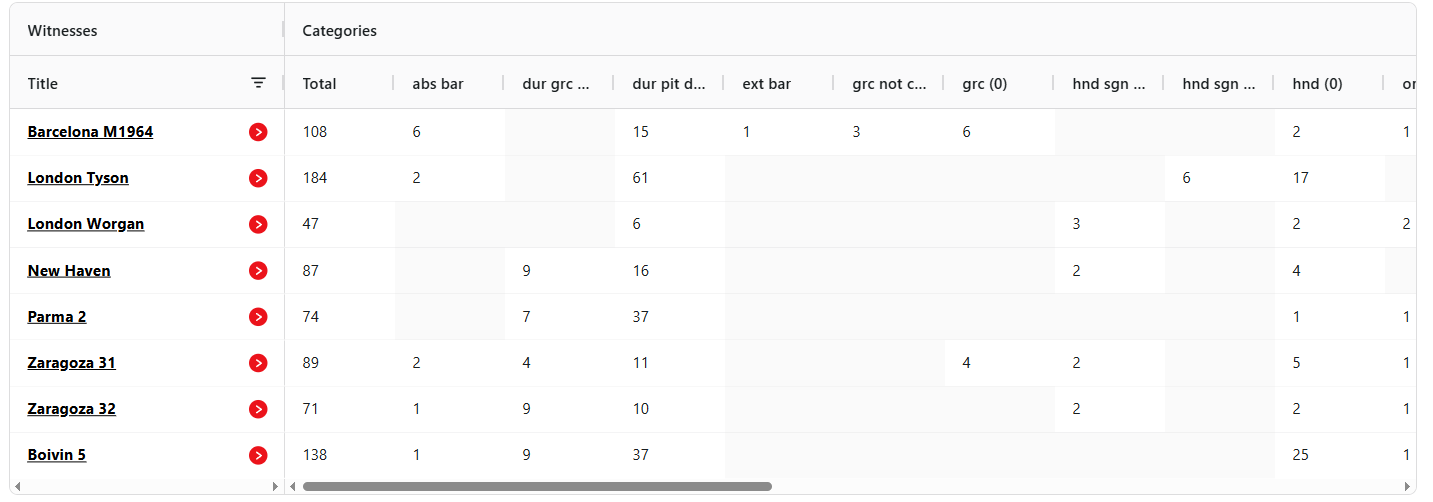
The full variant analysis table is available on the dedicated page for K48. Note, for instance, the relatively high number of pitch differences between the control (Venice 1742) and several of the witnesses. For a full list of variants please consult our variant dictionary.
The following is an extract from a detailed listing of complete matches (i.e. when the same variants in a bar, collated in the same way, appear in both witnesses) between two of the witnesses for K48, in this case Barcelona M1964 and Boivin 5:
Bar 26: 1] +eflat8 ; 4] +g,8 ; 7] +aflat,8
Bar 28: 5eflat”] -flat
Bar 49: 1g’] 16 ; 2g”] 16
Bar 51: 5] +fsharp”16 ; 6] +g”16
Bar 55: 5] +fsharp’16 ; 6] +g”16
Bar 83: 6aflat’] -flat ; 9aflat’] -flat
Bar 84: 5e’] -natural ; 8e’] -natural
Bar 86: 5e’] -natural ; 8e’] -natural
Bar 87: 6aflat’] -flat ; 9aflat’] -flat
Bar 105: 5b’] -natural ; 8b’] -natural
Bar 112: 5] +b”16 ; 6] +c”16
Bar 116: 5] +b”16 ; 6] +c”16
This level of detail is available for every sonata in the Sonatas section of this site. When replicated across all witnesses of each sonata it shows the benefit of developing a machine-readable coding system without which it would be impossible to process the number of potential relationships in question.
Consanguinity between texts can be illustrated in different ways, one of which is the conventional family tree:
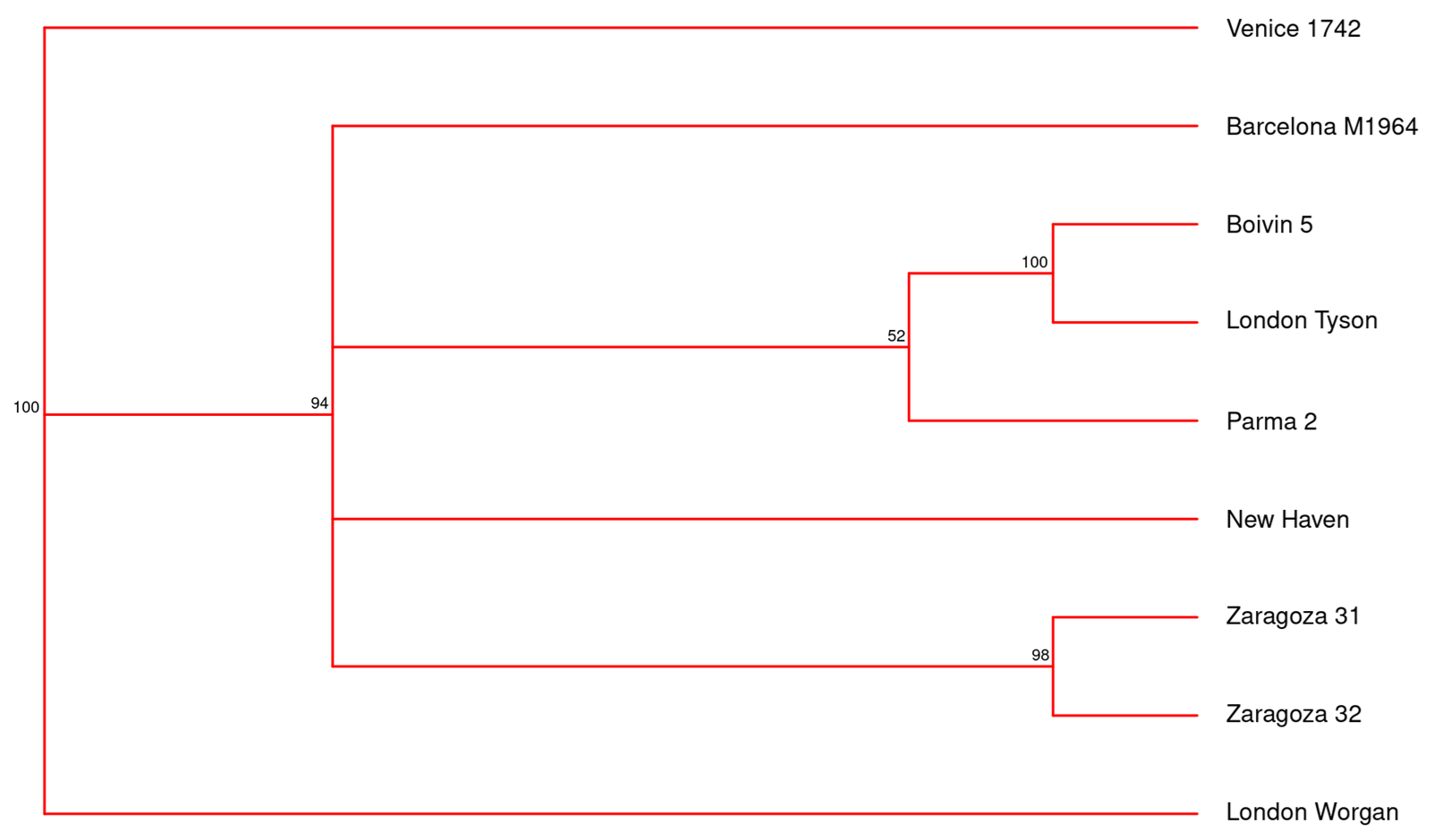
The small numbers indicate the degree of confidence the computer has in a particular grouping. The format has the advantage of familiarity, but there is also a risk of treating the control as the common ancestor. This may or not be the case. A better, because less hierarchical, diagram results from the Neighbor-Net method:
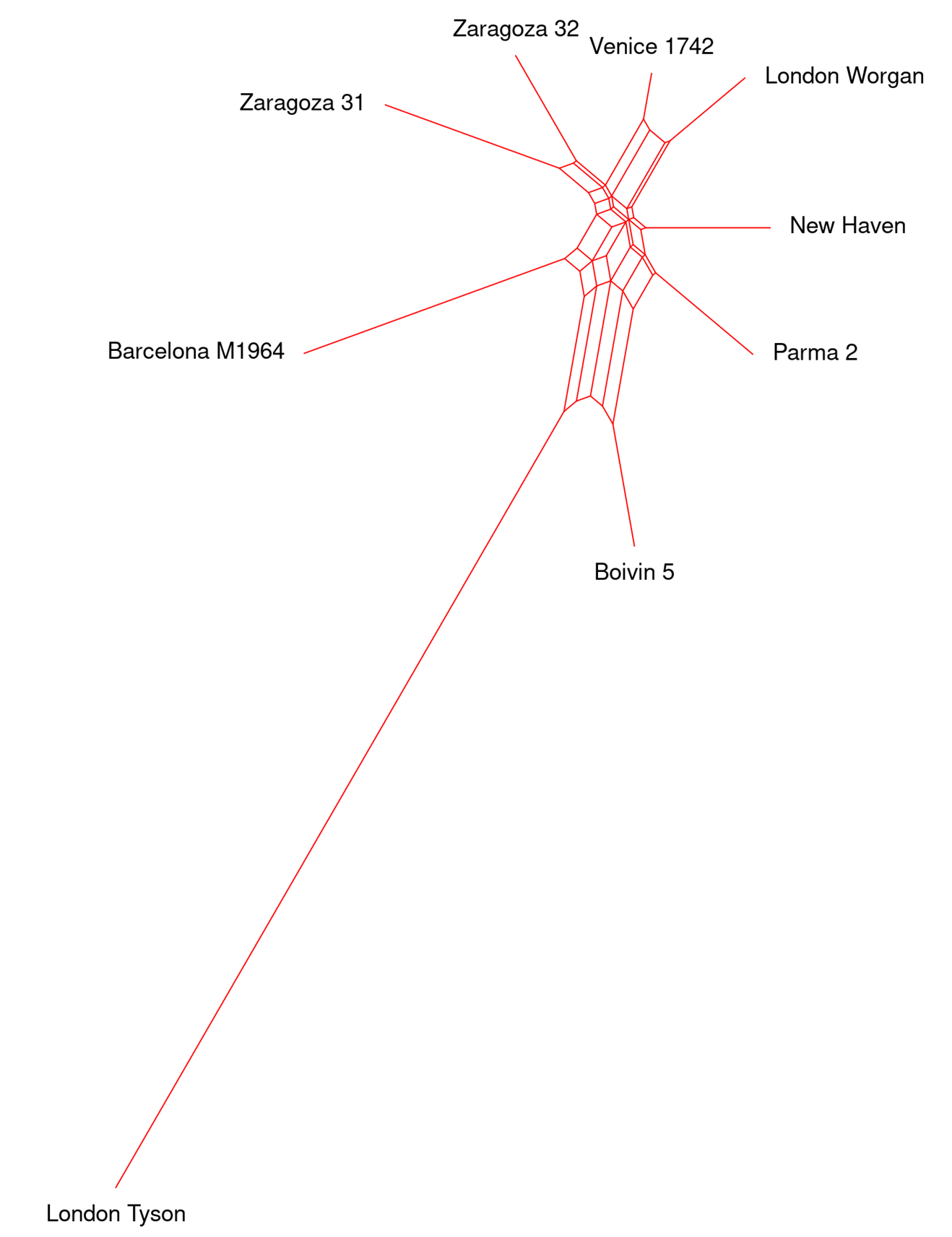
London Tyson is a clear outlier because this witness ends at bar 85, making it 39 bars shorter than the control (Venice 1742).
At all times, it is important to remember that data alone do not answer questions. But data can point us to the questions that we might want to ask. In the examples above, it is interesting to note that, leaving aside the difference in length, two witnesses, London Tyson and Boivin, have features in common that they do not share with the rest; while Venice 1742 and Parma 2 show more differences than might be expected from two collections that emerged from the same royal stable. Answers to these and many other questions posed by the data require the skill and judgment of the practitioner/researcher.
